반응형
타이타닉 데이터 분석 및 머신러닝 적용 목차
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #1 데이터 내용 및 객실등급(Pclass), 성별(Sex)확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #2 나이(Age)와 탑승위치(Embarked) 확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #3 형제자매,배우자(SipSp) 확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #4 데이터 정리 및 Feature Engineering
- [머신러닝 기초] 타이타닉 생존율 데이터 가공 - Machine Learning을 위한 데이터 처리 방법
- [머신러닝 기초] 타이타닉 생존율 모델링 - Predictive 모델링
- [머신러닝 기초] 타이타닉 생존율 분석 - Cross Validation
- [머신러닝 기초] 타이타닉 생존율 모델링 최적화 - 앙상블(Ensemble)
머신러닝은 모든 것을 숫자로 표현해야 하기 때문에 문자열로 정의된 값들은 숫자로 변환한다. 예를 들어 Sex(Male, Female), Embarked(S,Q,C) 등
data['Sex'].replace(['male','female'],[0,1],inplace=True)
data['Embarked'].replace(['S','Q','C'],[0,1,2],inplace=True)
data['Initial'].replace(['Mr','Mrs','Miss','Master','Other'],[0,1,2,3,4],inplace=True)기존 Data에서 필요없는(사용할 필요가 없는) 데이터는 제외한다. Name, Age(Age_band로 대체), Ticket, Fare(Fare_cat으로 대체), Cabin(Null값이 엄청 많고, 많은 승객들이 여러개의 Cabin을 가지고 있으므로 제외), Fare_Range(Fare_cat으로 대체), PassengerID(카테고리화 될수 없음)
data.drop(['Name','Age','Ticket','Fare','Cabin','Fare_Range','PassengerId'],axis=1,inplace=True)
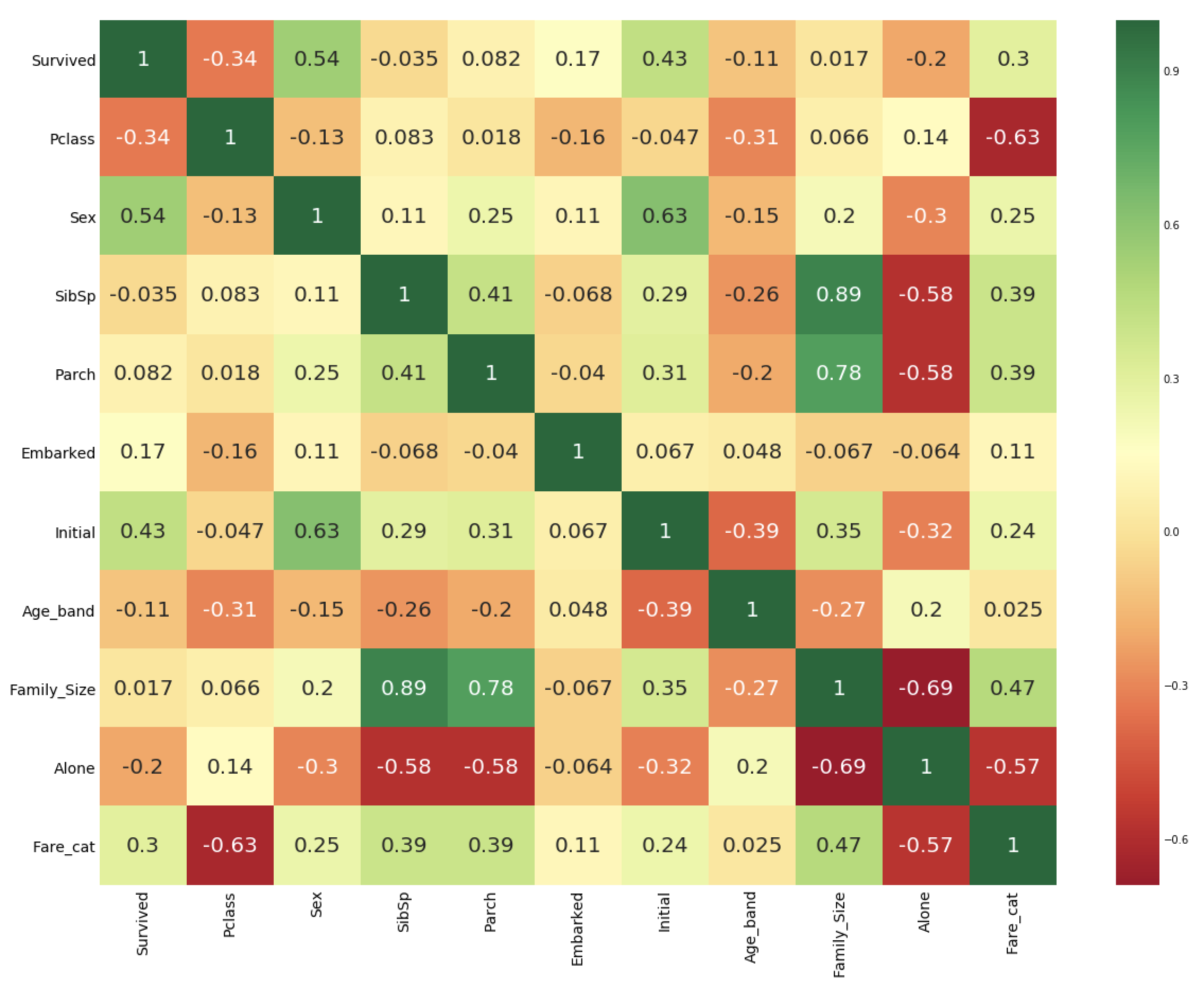
sns.heatmap(data.corr(),annot=True,cmap='RdYlGn',linewidths=0,annot_kws={'size':20})
fig=plt.gcf()
fig.set_size_inches(18,15)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()그래서 heatmap으로 상관관계를 살펴보면 positive 는 SibSp와 Family_Size, Parch와 Family_Size, Negative는 Alone과 Family_Size 로 알 수 있다
* 해당 타이타닉 notebook은 Kaggle의https://www.kaggle.com/ash316/eda-to-prediction-dietanic분석을 그대로 따라하면서 나름대로 정리한 부분임을 밝혀둔다.
반응형



