반응형
타이타닉 데이터 분석 및 머신러닝 적용 목차
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #1 데이터 내용 및 객실등급(Pclass), 성별(Sex)확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #2 나이(Age)와 탑승위치(Embarked) 확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #3 형제자매,배우자(SipSp) 확인
- [머신러닝 기초] 타이타닉 생존율 데이터 분석 - EDA #4 데이터 정리 및 Feature Engineering
- [머신러닝 기초] 타이타닉 생존율 데이터 가공 - Machine Learning을 위한 데이터 처리 방법
- [머신러닝 기초] 타이타닉 생존율 모델링 - Predictive 모델링
- [머신러닝 기초] 타이타닉 생존율 분석 - Cross Validation
- [머신러닝 기초] 타이타닉 생존율 모델링 최적화 - 앙상블(Ensemble)
Ensembling
앙상블은 모델의 성능이나 정확도를 높이는 데 좋은 방법이다.
- Voting Classifier
- Bagging
- Boosting
Voting Classifier
많은 다른 머신러닝 모델로 부터 prediction을 합치는 가장 간단한 방법이며 이것은 submodel의 prediction에 근거한 prediction 결과의 평균을 낸다.
from sklearn.ensemble import VotingClassifier
ensemble_lin_rbf=VotingClassifier(estimators=[('KNN',KNeighborsClassifier(n_neighbors=10)),
('RBF',svm.SVC(probability=True,kernel='rbf',C=0.5,gamma=0.1)),
('RFor',RandomForestClassifier(n_estimators=500,random_state=0)),
('LR',LogisticRegression(C=0.05)),
('DT',DecisionTreeClassifier(random_state=0)),
('NB',GaussianNB()),
('svm',svm.SVC(kernel='linear',probability=True))],
voting='soft').fit(train_X,train_Y)
print('The accuracy for ensembled model is : ',ensemble_lin_rbf.score(test_X,test_Y))
cross=cross_val_score(ensemble_lin_rbf,X,Y,cv=10,scoring="accuracy")
print('The cross validated score is',cross.mean())위에서 사용했던 모델들을 모두 VotingClassifier에 넣어서 Accuracy를 측정해보면 83%정도로 기존에 단독으로 돌렸던 accuracy보다 높게 나오는 것을 알 수 있다.

Bagging
Bagging은 일반적인 앙상블 모델로써 작은 크기의 데이터셋에 대한 유사한 classifier들을 적용한다. 그리고 나서 모든 prediction의 평균을 가져온다. 평균값으로 인해 variance를 줄일 수 있다.
Bagged KNN
from sklearn.ensemble import BaggingClassifier
model=BaggingClassifier(base_estimator=KNeighborsClassifier(n_neighbors=3),random_state=0,n_estimators=700)
model.fit(train_X,train_Y)
prediction=model.predict(test_X)
print('The accuracy for bagged KNN is : ',metrics.accuracy_score(prediction,test_Y))
result=cross_val_score(model,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for bagged KNN is: ',result.mean)역시 앙상블을 통해 accuracy가 올라가는 것을 확인 할 수 있다.

Bagged DecisionTree
model=BaggingClassifier(base_estimator=DecisionTreeClassifier(),random_state=0,n_estimators=100)
model.fit(train_X,train_Y)
prediction=model.predict(test_X)
print('The accuracy for bagged Decision Tree is : ',metrics.accuracy_score(prediction,test_Y))
result=cross_val_score(model,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for bagged Decision Tree is : ',result.mean())DecisionTree를 앙상블로 돌려봐도 역시 accuracy가 올라가는 것을 알 수 있다.

Boosting
Boosting은 연속적인 classifier를 learning함으로 써 앙상블을 사용하는 방법이다. weak모델을 강화하는 데 도움이 된다. 모델은 처음에 완전한 데이터셋으로 트레인되고, 다음 interation에서 잘못된 predicted instances로 이동하면 weight를 더 준다. 그래서 잘못된 instance를 정확하게 예측하도록 한다.
AdaBoost(Adaptive Boosting)
from sklearn.ensemble import AdaBoostClassifier
ada=AdaBoostClassifier(n_estimators=200,random_state=0,learning_rate=0.1)
result=cross_val_score(ada,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for AdaBoost is:',result.mean())weak learner 혹은 estimator가 Decision Tree이다. default base_estimator를 변경할 수 있다.

Stochastic Gradient Boosting
from sklearn.ensemble import GradientBoostingClassifier
grad=GradientBoostingClassifier(n_estimators=500,random_state=0,learning_rate=0.1)
result=cross_val_score(grad,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for Gradient Boosting is : ',result.mean())weak learner는 Decision Tree이다.

XGBoost
import xgboost as xg
xgboost=xg.XGBClassifier(n_estimators=900,learning_rate=0.1)
result=cross_val_score(xgboost,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for XGBoost is : ',result.mean())XGBoost가 일반적으로 성능이 제일 잘 나온다고 하던데, 여기에서는 그렇지 않은듯..

AdaBoost에서 가장 좋은 accuracy를 얻었기 때문에 AdaBoost로 Hyper-Parameter Tuning을 한다.
n_estimators=list(range(100,1100,100))
learn_rate=[0.05,0.1,0.2,0.3,0.25,0.4,0.5,0.6,0.7,0.8,0.9,1]
hyper={'n_estimators':n_estimators,'learning_rate':learn_rate}
gd=GridSearchCV(estimator=AdaBoostClassifier(),param_grid=hyper,verbose=True)
gd.fit(X,Y)
print(gd.best_score_)
print(gd.best_estimator_)n_estimators는 200, learning_rate는 0.05일 때 최고 accuracy를 알 수 있다.
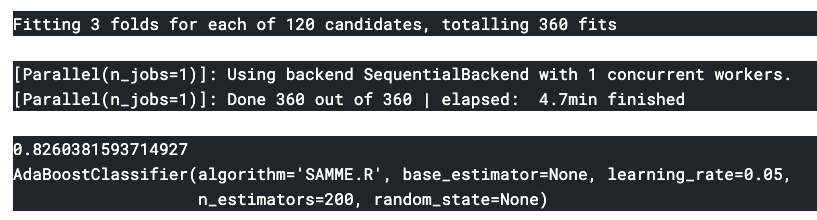
이렇게 찾은 최적의 모델에 대한 Confusion Matrix
ada=AdaBoostClassifier(n_estimators=200,random_state=0,learning_rate=0.05)
result=cross_val_predict(ada,X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,result),cmap='winter',annot=True,fmt='2.0f')
plt.show()위에서 했던 confusion matrix보다 survived, dead의 잘못된 예측이 조금 줄어든 것을 알 수 있다.
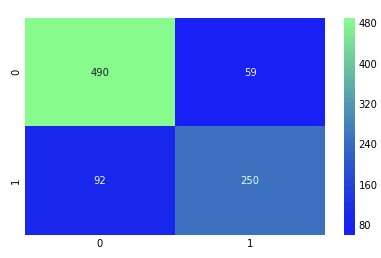
Feature Impartance
f,ax=plt.subplots(2,2,figsize=(15,12))
model=RandomForestClassifier(n_estimators=500,random_state=0)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[0,0])
ax[0,0].set_title('Feature Importance in Random Forests')
model=AdaBoostClassifier(n_estimators=200,learning_rate=0.05,random_state=0)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[0,1],color='#ddff11')
ax[0,1].set_title('Feature Importance in AdaBoost')
model=GradientBoostingClassifier(n_estimators=500,learning_rate=0.1,random_state=0)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[1,0],cmap='RdYlGn_r')
ax[1,0].set_title('Feature Importance in Gradient Boosting')
model=xg.XGBClassifier(n_estimators=900,learning_rate=0.1)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[1,1],color='#FD0F00')
ax[1,1].set_title('Feature Importance in XgBoost')
plt.show()Random Forest, AdaBoost, Gradient Boosting, XgBoost를 통해 Feature의 중요도를 판별한다. 각 알고리즘 별로 중요도는 조금씩 틀리게 나오는 것을 확인 할 수 있고, Initial의 값들이 가장 중요한 것으로 보인다. 그런데 특이한 점은 여자일 경우 생존율이 높다라고 계속 확인을 했지만 실제로 알고리즘에서는 Sex의 중요도는 낮은 것을 알 수 있다.
* 해당 타이타닉 notebook은 Kaggle의https://www.kaggle.com/ash316/eda-to-prediction-dietanic분석을 그대로 따라하면서 나름대로 정리한 부분임을 밝혀둔다.
반응형



